

The tokenmaxxing hangover.
Is your stack ready for the real bill?

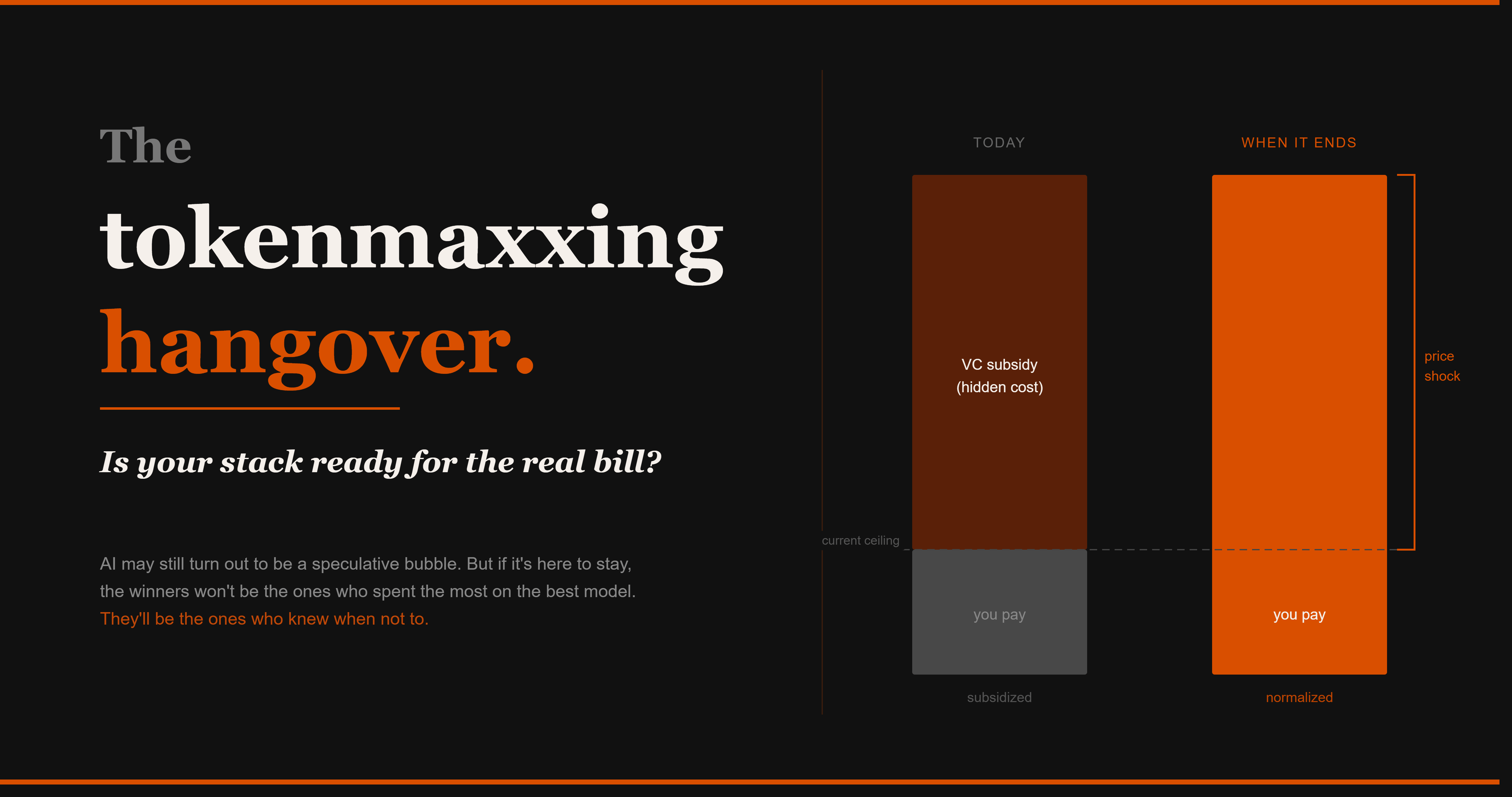
The other week OpenAI’s finances were leaked to Ed Zitron and verified by the Financial Times. The numbers are astonishing: $13.07B in revenue against $34B in total costs, a $20.9B operating loss and a headline net loss of $38.5B — inflated by a one-time non-cash charge, with the real cash burn closer to $8B.
More telling than the headline figure is the inference line: cash spent on serving model outputs alone was $3.8B in 2024, ballooning to $8.65B in just the first nine months of 2025 — more than double the prior year’s pace.
This raises obvious questions about OpenAI’s investor story.
But it raises a more pressing question for everyone else in the tech ecosystem: if the company serving the tokens is bleeding this badly, how much are the rest of us actually paying for what the tokens cost to produce?
The answer, increasingly, is: a fraction. OpenAI, Google, Anthropic and Meta are all pricing inference below cost to capture market share. Or in other words: a false floor on market prices, subsidized by what looks like seemingly endless venture and strategic capital. It won’t hold indefinitely.
Enterprises are already feeling the early tremors. As recently as a few weeks ago, companies like Meta, Amazon, and OpenAI were actively encouraging employees to maximize token usage — treating it as a proxy for AI productivity, with informal leaderboards tracking who could burn the most.
Uber burned through its entire 2026 token budget in the first four months of the year, largely through Claude Code usage. Salesforce is looking at a $300 million Anthropic bill, and its CEO is now publicly wishing for a “smart router” to determine which queries actually need the most expensive models. Uber’s COO put the problem plainly: if you can’t draw a direct line from token spend to useful features shipping to users, the costs are harder to justify.
The tokenmaxxing era is over, even though the subsidy that made it painless is still in place.
Part of the problem is structural.
The primary cost of AI has shifted from training models to running them — inference — and increasingly to running networks of agents that call each other in sequence or in parallel to complete workflows. Token prices have fallen consistently, which creates an illusion of decreasing costs.
But a Stanford, Berkeley, and CMU research team recently punctured that illusion with what they call the price reversal phenomenon: in nearly a third of model comparisons, the cheaper-listed model actually costs more in practice — sometimes dramatically more. Gemini 3 Flash’s listed price is 80% cheaper than GPT-5.4, but its actual cost across real tasks runs 38% higher.
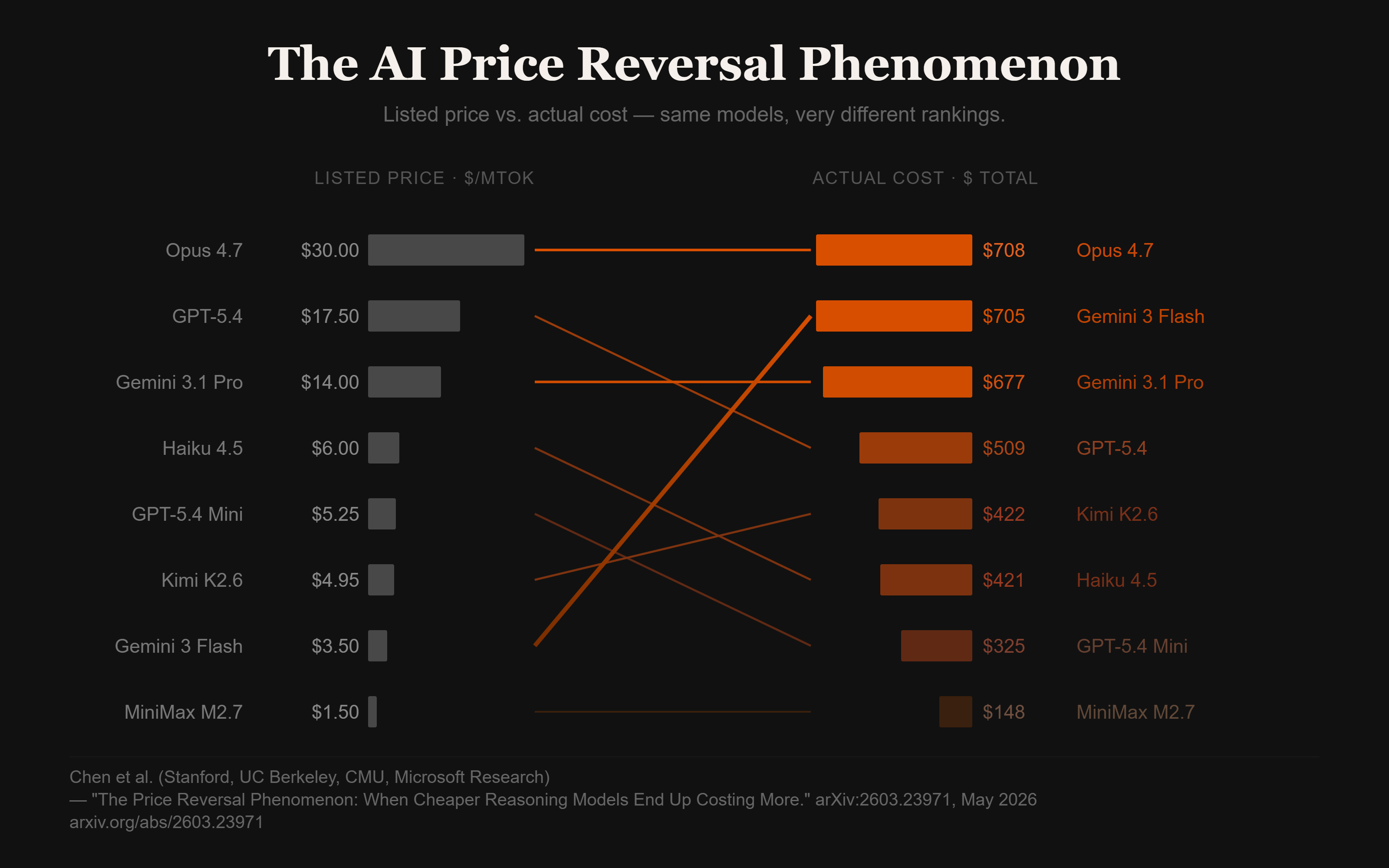
The reason is thinking tokens: a more efficient model may charge more per token but use far fewer of them, while a “cheap” model burns through vastly more compute to reach the same answer — or fail to reach it at all.
Which brings in the second finding, and the more damning one. Researchers at The AGI Company, Stanford, and Oxford assembled 112 practical tasks mirroring the kinds of multi-step interactions enterprises are actually trying to automate — booking, e-commerce, communication, and scheduling. Tested across 11 realistic website environments, frontier models succeeded on at most 41% of them. Which means that for agentic workflows — the high-token-burn use cases everyone is building toward — the majority of spend is currently going toward hallucinated or failed results.
So we’re in for a recalculation. Several forces are converging at once:
The current pricing is subsidized, and the gap between list price and true cost will narrow as the market matures.
Listed prices don’t map neatly to real-world costs anyway, because token consumption is unpredictable and model efficiency varies wildly by task. And the agentic workflows now eating the most tokens are also the ones delivering the least reliable results — while the bill runs regardless.
These aren’t problems isolated to AI labs.
Every company is now an AI company in some meaningful sense: either a thin wrapper over a model, or a traditional product with AI features bolted on, or a team of people who’ve replaced workflows with AI tools to do more with less.
Developers orchestrate fleets of models to write, review, and ship code. Non-technical workers run their days through AI assistants. CFOs are watching the line items and asking a question that’s getting harder to answer: where’s the ROI — and what happens to our margins if prices move in the wrong direction?
The answer is smarter logistics and diversification.
Think of it like a supply chain.
A company that sources everything from a single premium supplier at full price is the most exposed when that supplier raises rates. The smart move is diversifying the models based on use cases, where each one is used for what they do best, at the price point that matches the task.
Inference infrastructure is now being built exactly on this model. While financial headlines focus on GPU manufacturers and frontier labs, a quieter category is emerging: companies that take open-source model weights, run them efficiently on GPU clusters, and offer them as APIs — so developers aren’t locked into a single frontier provider for every call.
Featherless, Fireworks AI, Together AI and Baseten are all building versions of this. Above them sits another layer: routers that direct each request to whichever provider is cheapest or fastest for that specific task in real time. OpenRouter, now processing 25 trillion tokens a week — up from 5 trillion just months ago — is the clearest example of how quickly this market is moving.
The practical implication is straightforward: a company running GPT-4o on every workflow is paying a premium today and maximally exposed to a correction tomorrow.
The path off that exposure is routing high-volume, low-complexity calls to smaller open-source models and reserving frontier APIs for the steps where quality genuinely matters. The infrastructure to do this cheaply and without friction now exists and is raising money at eye-watering valuations — because the bet is that enterprises will need an exit ramp sooner than most of them expect.
AI may still turn out to be a speculative bubble. But if it’s here to stay, the winners won’t be the ones who spent the most on the best model. They’ll be the ones who knew when not to.
And most companies haven’t noticed yet.